
Hello and welcome back!!
In the last article, we covered the evolution, importance and scope of Machine Learning.(It is strongly recommended that you read Part-1 of this article if you are new to Machine Learning. Consider it as a prerequisite. Read it by clicking here) Now, we will look at the different techniques which are commonly used to implement these, and the steps to be followed. If this is your first time, do not get overwhelmed by the technical jargon. The basis of it is simple enough.
There are two approaches to start a problem- algorithms based on rule based learning, and algorithms based on similarity. It is related to how much freedom the machine has to learn, that is, if you want to let it train itself based on the input or you want it to train based on some provided understanding. This brings us to the various kinds of learning techniques of machine learning.
Learning Techniques:
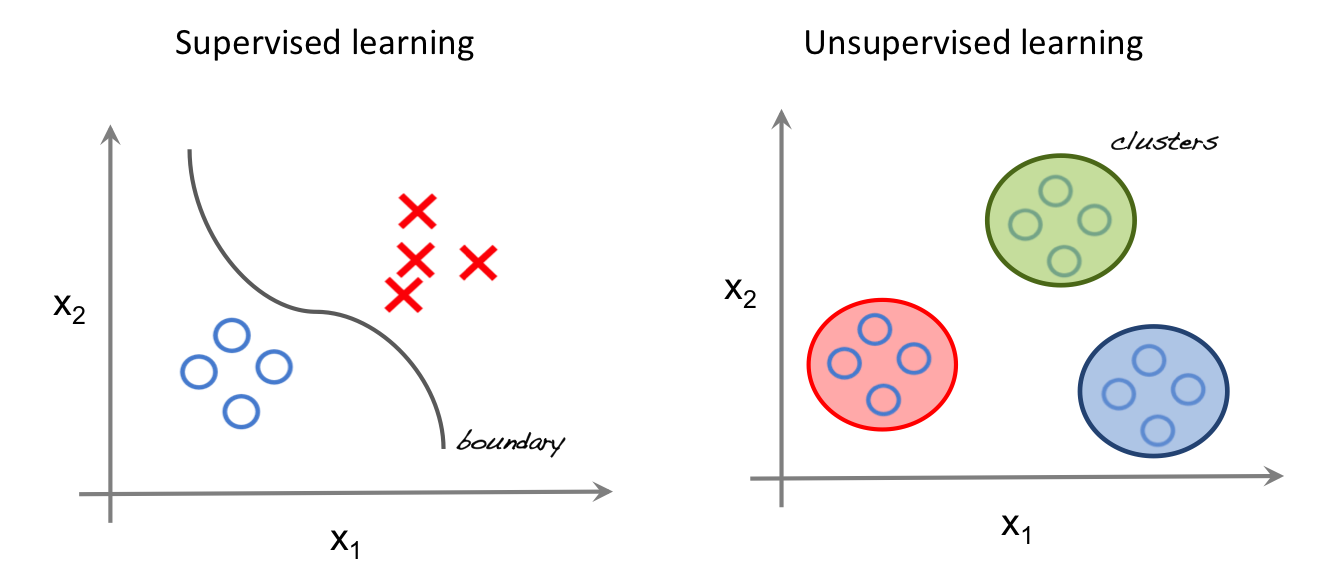
1. Supervised Learning:
As the name suggests, a supervised algorithm is implemented when you have labels for the values you use. This means that you know what data the machine is being trained on, and you can group it accordingly.
Take an example: You are trying to build a system which identifies whether a person is tall or short. You have the data in the form of a table, which has features such as Gender and Age, which have a direct stated relation to the output(Suppose gender being female would push classification towards a shorter height and vice versa for the male gender)This is supervised because you know what the data is and how it relates to the output.
Basically, we provide input data (a labelled set) and using a set of predictors predict an unknown target. Think of it as a very calculated approximation. You decide a function such that f(x)=y. Pretty simple!
One of the issues with supervised learning is that it relies heavily on our understanding. Thus, it introduces a bias in the learning because of the human intervention, and so accuracy can be a problem. Common examples of supervised algorithms are: Naive Bayes, Decision Trees, Linear Regression, Support Vector Machines (SVM), k- Nearest Neighbour (KNN).
2. Unsupervised Learning:
In this technique, we have an unlabeled input data set and the model is based on the similarity that the machine deduces in the data structure.
Take an example: I give you a bowl of fruits
The fact that the machine can find patterns in data helps in cases where we cannot see anything. It is used in pattern detection and descriptive modelling. It gives meaningful insight into the data that might appear irrelevant to us. Common examples are: Apriori algorithm, K-means.
3. Semi-Supervised Learning:
In this technique, we use supervised learning methods, and also unlabelled data, as in unsupervised learning. Basically it makes use of a small amount of labelled data and a huge amount of unlabelled data. This this techniques is midway between Supervised and Unsupervised learnings.eg. Regression and Classification algorithm.
4. Reinforced Learning:
In this technique, the machine is trained within a specific horizon. It is exposed to an environment and it learns from the changes in it's surroundings by trail and error to determine the ideal behavior in a certain scenario. With the help of this, the machine minimizes the risk and maximizes the award. Common examples are: Q-Learning, Temporal Difference (TD), Deep Adversarial Networks.

Machine learning is cool, isn't it? But heading out as beginners, you must have been tired of the mathematical aspects of it, or, you may be fed up of the blogs targeted at intermediate level users.
The solution is following a top-to-bottom approach
What it means is using applied machine learning to get a feel of all the algorithms and then dwelling deep into more complex algorithms and the mathematical aspects. Once you start understanding the outer mantle, the difficult part becomes interesting, and you appreciate the challenge. A general layout is to learn the high-level aspects, know the tools properly, practice on a lot of data-sets and then get into the lower-level aspects of machine learning.
Steps to make your machine learn:
Following is a 5-step model for deploying any machine learning model for almost any problem:
-
Define problem statement: The What, Why and How of the statement should be very clear before starting to solve the problem. The problem should be very clearly described and a thought must be given to how such a problem could be tackled manually before assigning it to the machine.
-
Data Collection: Clearly analyse the data that is available and start collecting all the relevant information into a database, e.g. while making a spam classifier, you must have relevant number of spam and ham(not spam) e-mails before starting the processing step.
-
Data pre-processing: Everything that you collect as data might not be relevant and tailoring it for your own use will make your algorithm faster. For example, removing the irrelevant images with very less information to process or, deleting articles (a, an, the) prevents wasting time. At the same time, you need to split the data-set into training and test sets. Pre-Processing is often regarded as the most important part of machine learning.
-
Build a relevant model: The training data set is used to create a relevant model to predict an unknown target. Not all algorithms work equally efficiently for all problem statements. You need to develop a baseline accuracy based on previously implemented models on the same problem and then spot check algorithms i.e. testing different standard machine learning algorithms to see which one gives the best results.
-
Evaluate and improve: More accurate models can be made by combining multiple models to get more accurate results. Again, it is a trade-off between time and accuracy. So, choose accordingly and finally deploy your model for others.
Now that you know what the various kinds of algorithms used in machine learning are and the steps to implement them, you must be eager to know what these algorithms actually are. What is the logic behind them? Well in simple words Machine Learning makes extensive use of probability and calculus combined with linear algebra to make classification or prediction models. But, don't worry, even if you don't like too much of Math, you still can be a good Machine Learning practitioner. Just be dedicated to getting the hang of how to implement it.
In our next article we will approach one of the simplest supervised ML algorithm, the Naïve Bayes method. We will be looking at how it actually works, and code it from scratch. Also we will be using the cool inbuilt libraries to make our work easy. The language we will follow is Python, a simple to type language with neat support for libraries. Don't fret if you aren't familiar with Python, it is similar to Java and C++, and is much easier to understand. Plus, we will be explaining how the code works, so we've got you covered.
See you at the next post!! Cheers!