
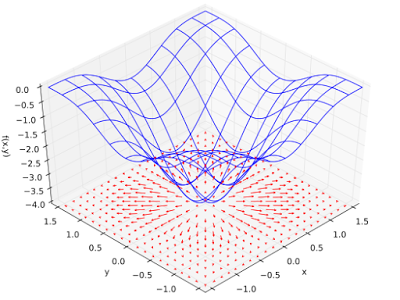
This is the visual representation of the loss with respect to the function. The aim of our model is to create the model with the least loss. The "Gradient Descent" algorithm does this exactly. Based on the parameters we have, the algorithms creates multiple models to find out the best model. Now we have to keep two things in mind- number of epochs and learning rate. These are the terms that are the centerpiece of the algorithm.
Number of Epochs
Number of epochs is the number of times the algorithm undergoes the learning process. Essentially, larger the number of epochs, the model should get better at the training data. Nevertheless, it takes longer to complete the training process and may even lead to over-fitting in case of large values.
As each epoch passes, the loss keeps on decreasing and is supposed to converge to a minimum and the bottom of the curve. How much does the loss value decrease is determined by the learning rate. Learning rate is essentially the step size of the algorithm. As we go downhill, the learning rate decides how fast we reach the bottom valley. A smaller step size means that the algorithm is more likely to arrive to the minimum cost but we may not even reach the deepest end. A higher learning rate ensures that we reach the deepest end but we may not arrive at the minimum cost.
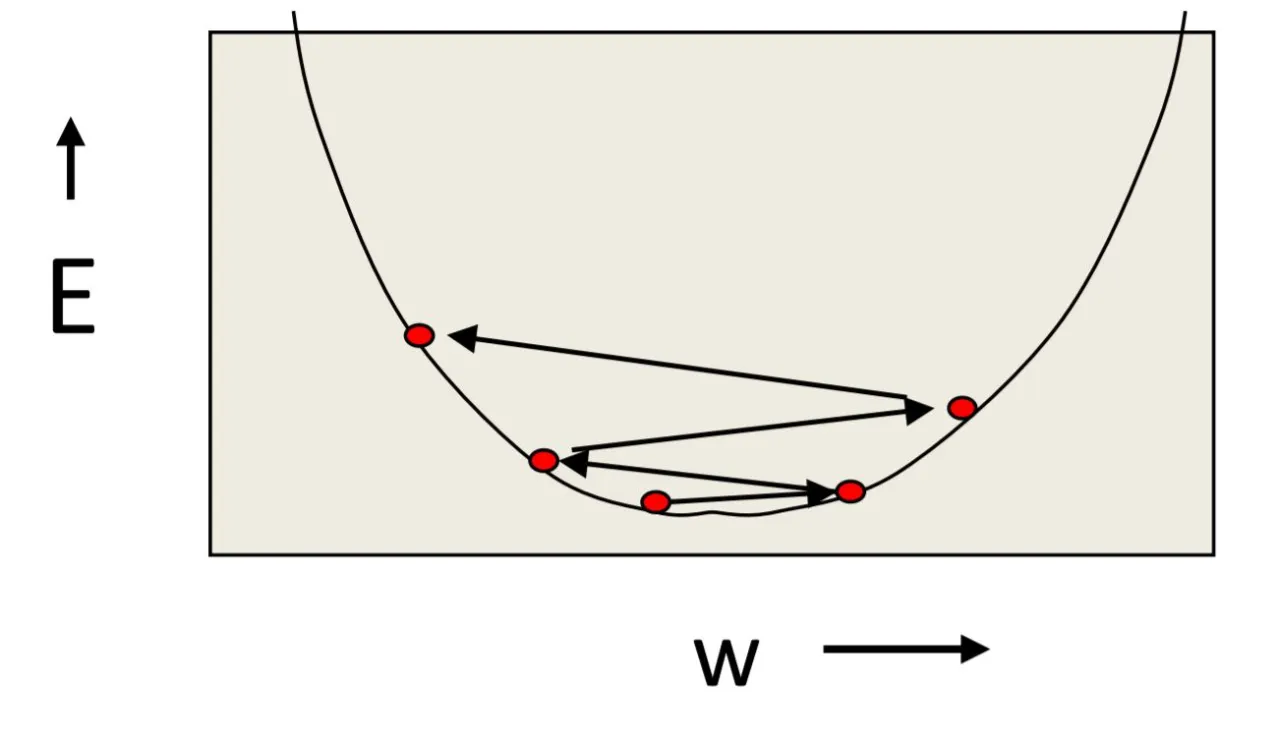 Courtesy: CS231n by Prof. Geoffrey Hinton
Courtesy: CS231n by Prof. Geoffrey Hinton
If the learning rate is too big, we may move to and fro across the curve and may even diverge from the lowest value. If it is too small, we may never reach it.
So how do you choose them?
The number of epochs and the learning rate is chosen by more or less, a hit-and-trial method. We start with a learning rate value like 0.1 and then after cross-validation, we modify the value accordingly. It may range anywhere from 0.0001 to 1. For the number of epochs, we need to make sure that model does not overfit the training data which may result in decrease in it's accuracy. This can be prevented by early stopping or regularization. You will learn more about all this as we proceed towards deep learning models and neural networks.